-
MIND: A Large-scale Dataset for News Recommendation 논문 한글 요약 - 2일상/학기 중 일기 2024. 6. 4. 21:10
해당 논문의 나머지 부분을 요약해보았다.
1부는 아래 링크를 통해 확인 가능하다.
MIND: A Large-scale Dataset for News Recommendation 논문 한글 요약 - 1
졸업 프로젝트 준비로 뉴스 추천 시스템을 공부하고 있는데, MIND 데이터셋 관련 논문을 읽다가 한국말로 정리해보았다.중간 부분까지 읽으면서 요약을 했고, 나머지 부분은 2편으로 만들어 올릴
parksoffice.tistory.com
4 방법
일반적인 추천 방법과 뉴스에 특화된 추천 방법이 있음. 그리고 각각의 방법들은 각기 다른 설정과 데이터셋들을 이용해 개발되었음. 여기서는 이들을 다 MIND데이터셋을 사용하여 비교할 예정.
4.1 일반적인 추천 방법들
LibFM(Rendle,2012): factorization machine에 기반한 고전적인 추천 방법. userID, newsID외에도 이전에 클릭된 뉴스들과 후보뉴스들에게서 뽑아낸 내용 특성들을 사용하여 유저와 후보 뉴스들을 표현함
등등
4.2 뉴스 추천 방법들
Deep fusion model, autoencoder(latest news representation), GRU(user representation), CNN, personalized attention mechanism, attentive multi-view learning, LSTM, short-term with GRU, long term from the whole click history, multi-head self-attention 등을 사용
5 실험들
5.1 실험 세팅
대부분의 추천 방법들이 뉴스 제목을 기반으로 만들어짐. 그래서 공정성을 위해 제목만을 이용함. 5.3.3에서는 각각 다른 뉴스 텍스트(body 등)의 유용성에 대해서 살펴볼 예정. 현실의 시나리오에서는 학습에서 다뤘던 유저가 아닌 새로운 다른 유저들이 포함되므로, 랜덤하게 절반의 유저를 데이터에서 뽑아 학습시키고, 테스트 과정에서는 전체 유저를 사용함. Word embedding이 필요한 방법들의 경우, Glove를 이용함. Optimizer로는 Adam을 사용함. 그리고 impression log에는 대부분 클릭했던 뉴스들 보다 클릭하지 않았던 뉴스들이 더 많으므로, model training을 위해 negative sampling 기법을 사용함. 모든 hyperparameter들은 validation set의 결과를 통해 선택됨. 사용된 metric은 AUC, MRR, nDCG@5, nDCG@10을 사용함. 이들은 추천 결과를 평가할때 사용되는 표준 metric들임. 각각의 실험은 10번 반복됨.

5.2 성능 비교
- 뉴스에 특화된 추천 방법들(NAML, LSTUR, NRMS)이 대체로 일반적(general)인 추천 방법들 (Wide&Deep, LibFM, DeepFM)보다 성능이 좋음. 왜냐하면 뉴스 기사의 표현들과 유저 관심도과 end-to-end manner로 학습되었기 때문. 일반적 추천 방법들은 이것들이 handcrafted feature로 표현됨. 이러한 결과는 뉴스 컨텐츠와 유저 관심도를 뉴럴 네트워크에 넣고학습시키는 것이 특성 공학적으로 접근하는 것 보다 효과가 우수하다는 것을 검증해줌. 한 가지 예외는 DFM이었는데, 뉴스 추천 시스템을 위해 디자인 되었지만, 일반적인 추천 방법들 (DSSM)보다 성능이 좋지 않았음. 이 이유는 DFM에서는 뉴스와 유저의 feature들이 직접 손으로 (manually) 디자인 되었기 떄문임.
- Neural news reommendation methods들 중에 NRMS가 성능이 제일 좋았음. NRMS는 mutli-head self-attention을 사용해서 단어 사이의 연관성을 학습하는 방식으로 뉴스 정보를 학습함. 그리고 이전에 클릭되었던 뉴스기사들 간의 상호작용을 포착하여 해당 유저의 특성을 학습함. 이 결과는 multi-head self-attention과 같은 advanced NLP 모델이 뉴스 컨텐츠와 유저의 관심도를 이해하는 능력을 효과적으로 개선시킬 수 있다는 것을 보여줌. LSTUR의 성능도 매우 좋았음. LSTUR의 경우, 유저의 최근 클릭된 뉴스들의 정보를 통해 얻어진 해당 유저의 short-term 관심도를 GRU네트워크를 통해 모델링하고, 유저의 long-term 관심도를 전체 뉴스 클릭 기록들을 통해 모델링함. 이러한 결과들은 유저의 관심도를 적절하게 모델링 하는 것도 뉴스 추천 시스템에 매우 중요하다는 것을 보여줌.
- AUC metric의 관점에서, training 데이터에 포함되었던 유저들인 overlap users보다 포함되지 않았던 unseen users에 해당하는 성능이 살짝 낮았음. 그러나 MRR, nDCG metric의 관점에서는 두 유저 분류간의 성능차이가 거의 없었음. 이러한 결과는, 이전 클릭된 뉴스들의 내용을 통해 유저의 관심도를 추론하므로써, 일부 유저들만을 통해서 학습된 추천 모델이 나머지 유저들과 미래에 새롭게 유입될 유저들에게도 효과적으로 적용될 수 있다는 것을 보여준다.
5.3 뉴스 내용 이해
여기서는 텍스트 정보를 통해 정확한 뉴스 정보를 학습하는 방법을 알아봄. MIND 데이터셋은 크기가 크므로, 랜덤하게 100,000개의 샘플들을 각각 training set과 test set에서 추출하여 실험에 사용함.
5.3.1 뉴스 표현 모델 (News Representation Model)
먼저, 뉴스 표현을 학습하기 위한 3가지 텍스트 표현 방법들을 비교해본다. 성능이 좋았던 3가지 뉴스 추천 방법들(NAML, LSTUR, NRMS)을 뽑고, 이들의 기존 뉴스 표현 모듈들을 다른 텍스트 표현 방법들(LDA, TF-IDF, word embedding 평균(Avg-Emb), CNN, multi-head self-attention(Self-Att))들로 대체해보았다. 또한 Attention mechanism은 NLP에서 중요한 기술이므로, 앞서 설명했던 뉴럴 텍스트 표현 방법들에 적용시켰다.
위 결과들을 통해 알아낸 점들이 몇가지 있는데, 다음과 같다.

- CNN, Self-Att, LSTM 과 같은 neural text representation method 들의 경우 기존의 텍스트 표현 방법(TF-IDF, LDA)보다 성능이 매우 뛰어났다. 이것은 neural text representation 모델들이 뉴스 추천 task들을 수행하면서 학습될 수 있기 때문이고, 뉴스 표현을 더 잘 생성할 수 있게끔 텍스트의 맥락을 포착한다.
- Self-Attention과 LSTM이 CNN보다 뉴스 표현에 있어서 성능이 매우 뛰어났다. 이것은 multi-head self-attention과 LSTM의 경우 단어들의 long-range context들을 포착할 수 있지만, CNN의 경우 오로지 지역적 context만 포착할 수 있기 때문이다.
- Attention mechanism이 앞서의 다양한 neural text representation methods(e.g. CNN, LSTM)의 성능을 효과적으로 개선시킬수 있다. 이는 attention을 이용해서 뉴스 텍스트 내의 중요 단어들을 골라내는것이 informative한 뉴스 표현을 학습하는데에 도움을 줌을 보여준다.
- LSTM과 attention을 결합한 것이 최고의 성능을 보여주었다.
5.3.2 Pre-trained Language Models
BERT와 같은 pretrained 언어모델을 news representation에 사용하는 것이 성능을 더욱 개선시키는 데에 도움을 주었다. (NAML, LSTUR, NRMS의 news representation module 에 사용)

이 BERT를 뉴스 추천 시스템에 fine-tuning 하여 성능을 더욱 개선시킬 수 있음. 뉴스 기사를 이해하는데에 pre-trained language model을 사용하는 것이 매우 큰 도움을 주는 것이 검증됨.
5.3.3 다른 뉴스 정보들
이번에는 뉴스의 abstract나 body와 같은 추가적인 정보를 포함하면 뉴스에 대한 더 나은 정보를 얻을 수 있는지 알아보자. 뉴스 텍스트 결합을 위해 두가지 방법을 시도해본다. 첫번째는 직접적인 연결 (direct concatenation)이다. 이는 각각의 다른 뉴스 텍스트를 붙여서 긴 document를 만들어내는 방법이다. 두 번째 방법은 multi-view learning으로, 각각의 뉴스 텍스트를 독립적으로 모델링하고, attention 네트워크를 사용하여 결합시키는 방법이다. 결과는 아래와 같다.
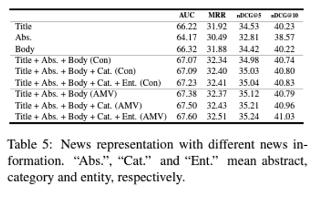
실험 결과 뉴스의 body가 title이나 abstract보다 뉴스 정보를 표현하는데에 효과적이라는 것이 확인됨. 이는 뉴스 body가 훨씬 길고, 뉴스 내용에 대한 훨씬 풍부한 정보를 담고있기 때문임. 그리고 각각의 다른 종류의 부분들(title, body, abstract)을 포함시키는 것이 뉴스 추천의 성능을 높이고, 뉴스 표현에 대해 상호 보완적인 정보를 담게됨을 보여준다.
또한 카테고리 라벨과 뉴스 텍스트 속 entity들을 포함시키면 성능을 더 높일 수 있다. 이는 카테고리 라벨이 일반적인 주제 정보를 제공할 수 있게되고, entity는 뉴스의 컨텐츠를 이해하기 위한 키워드로서 동작하기 때문이다.
또한, attentive multi-view learning model이 direct text combination보다 효과가 좋다는 것이 확인되었다. 이는 각각의 서로 다른 부분의 뉴스 텍스트가 대부분 서로 다른 특성을 갖고 있고, 이를 서로 다른 neural network를 통해 학습시키고, attention 메커니즘을 활용하여 그들의 서로 다른 기여도를 모델링 하는것이 더 낫기 때문이다.
5.4 유저 관심도 모델링
대부분의 최신 뉴스 추천 시스템들은 유저의 관심도를 이전에 클릭했던 뉴스 기사들을 통해 추론한다. 이 섹션에서는 각기 다른 유저 관심도 모델링 방법의 효과에 대해 알아본다. 6개의 모델을 비교했다. 이 모델들은 다음과 같다. 이전에 클릭된 뉴스들의 representation의 평균(Average), attention 메커니즘, candidate-aware attention(Candidate-Att), gated recurrent unit(GRU), long-short-term user representation(LSTUR), multi-head self-attention(Self-Att). 공정한 비교를 위해 이들 방법에 투입될 뉴스 representation들은 전부 LSTM으로 생성했다.
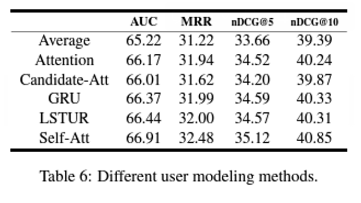
Attention, Candidate-Att, GRU 모두 평균(Average)보다 더 나은 결과를 보였다. Attention은 유저 representation을 만들기 위한 유용한 행동들을 골라낼 수 있고, Candidate-Att의 경우 유용한 정보를 골라내기 위해 후보 뉴스들의 정보를 포함시킬 수 있고, GRU의 경우 행동 정보들의 순서 정보를 포착할 수 있기 때문이었다.
LSTUR의 경우 위의 모든 방법들보다 성능이 우수했음. 왜냐하면 다른 시간 범위의 행동들을 이용해서 long-term과 short-term 유저 관심도를 모두 모델링할 수 있기 때문임. Self-Att도 마찬가지로 높은 성능을 보여주었는데, 긴 범위의 과거 유저 행동들의 연관성을 통해 더 나은 모델링이 가능하기 때문이다.
그리고 유저 관심도 모델링에 있어서 클릭 히스토리의 길이의 영향도 연구했는데, 아래에서는 각기 다른 길이의 뉴스 클릭 히스토리에 따른 3가지 뉴스 추천 방법들의 유저 표현 성능을 보여준다.

이는 유저에 대해 나타내는 성능이 일반적으로 더 긴 클릭 기록을 사용할 때에 나타남을 보여준다. 이러한 결과는 매우 직관적인데, 클릭 기록이 더 길수록 더 많은 유저 관심도에 대한 정보를 제공할 수 있기 때문이다. 그리고 위의 결과는 뉴스 플랫폼에서 데이터가 별로 많지 않은 유저에 대해서는 관심도를 추론해 내는것이 상당히 까다롭다는 것도 보여준다. (cold-start users)
6 결론
뉴스 추천 시스템을 위해서는, 뉴스 컨텐츠를 정확하게 이해하고 유저 관심도를 정확하게 모델링하는 것이 중요하다. 다양한 NLP, 머신러닝 테크닉들이 추천시스템의 성능을 높이는 데에 기여할 수 있다. (텍스트 모델링, 어텐션 기법, pre-trained 언어모델)
향후에는 뉴스 속 이미지와 비디오 정보들 또한 포함시키는 방향으로 MIND 데이터셋을 확장시킬 예정이다. 그리고 서로 다른 언어의 뉴스도 마찬가지. (multi-modal & multi-lingual news recommendation) 또한 클릭 정보 뿐만 아니라, read 와 engagement 정보도 포함시켜 더 정확한 유저 모델링과 성능 평가가 가능하도록 할 예정이다.
또한 MIND 데이터셋은 뉴스 추천 말고도, 주제 분류, 텍스트 요약, 뉴스 헤드라인 생성 등의 다른 NLP task에도 활용될 수 있다.
'일상 > 학기 중 일기' 카테고리의 다른 글
MIND: A Large-scale Dataset for News Recommendation 논문 한글 요약 - 1 (0) 2024.05.26 0503 - 인스타그램을 지울 용기 (2) 2024.05.03 0310 - 어떻게 나한테 이럴 수 있어 (4) 2024.03.11 0307 - 고마움은 마음속에 묻지 말고 표현하라. (3) 2024.03.07 0306 - 하늘이 무너져도 솟아날 구멍은 있다. 다만.. (0) 2024.03.07